Oceanverse
- Module 0
- Module A
- Module B
- Module C
- Module D
- Module E
- Module F
- Module G
- Module H
- Module I
- Module J
- Module K
- Module L
- Module M
- Module N
- Module O
Strictly use Geogebra to solve all the questions
Module 0
-
Plot the points \((2,3)\) and \((6,9)\) and find the distance between them without using the formula for distance.
-
Plot two vectors \(u=⟨3,−2⟩\) and \(v=⟨−1,5⟩\).
-
Find the angle between them.
-
Construct a perpendicular bisector of a given segment whose end points are \((0,6)\) and \((6,0)\).
-
Plot line \(y=3x\).
-
Graph the equation \(y=2x+3\) over the interval \([−5,5]\) and find the points where the graph intersects the x-axis and y-axis.
-
Explore the behavior of the quadratic function \(f(x)=x^2−4x+3\). Determine its vertex, axis of symmetry, and roots.
-
Find the angle between the lines with equations \(y=2x+3\) and \(y=−3x+2\).
-
Determine the angle of depression from the top of a building to a point on the ground 50 meters away from the base of the building, given that the height of the building is 30 meters.
-
Construct a right angled triangle with legs of lengths 3 units and 4 units. Find the length of the hypotenuse.
-
Find the centriod of the above triangle.
-
Enter a set of parametric equations, such as \(x(t)=cos(t)\) and \(y(t)=sin(t)\) to plot a circle.
-
Create two planes: Plane 1: \(2x−3y+z=6\), Plane 2: \(x+4y−2z=8\). Plot the two planes in a 3D coordinate system.
-
Determine the angle between the two planes. Are the planes intersecting? Is there any unique point in common? What do you infer from this?
Module A
1.Ram and Lakshman were two brothers, Ram’s pocket money was twice as Lakshman. The good boys that Ram and Lakshman were, they did not spend their pocket money on anything. They instead saved the same in their piggy bank. Every week, they would check their savings so far. Assume the first week’s savings was \((R_1,L_1)\) and second week’s \((R_2,L_2)\) and so on. They try plotting their weekly savings on a graph sheet. How will the points look like?
Sol.
In GeoGebra, if you plot the weekly savings of Ram and Lakshman on a graph with the x-axis representing Lakshman's savings and the y-axis representing Ram's savings the points will form a straight line. This is because Ram's savings are always proportional to Lakshman's savings. The points will follow a straight line passing through the origin as: $$y = 2x$$2.Atul’s house is centered at origin \((0,0)\) he walks straight (along the x-axis) for 2 units and then takes a left and walks 1 unit to reach Bala’s house, after that he takes a right turn and walks for one unit and then a left turn and walks for one unit and reaches Chetan’s house. He continues in a similar style, takes a right turn 1 unit and then left turn one unit and reaches Divya’s house. Are the houses of Bala, Chetan and Divya on a straight line? What is the equation of this line? Plot this on Geogebra
Sol.
3.Plot the lines \(y=x\), \(y=2x\), \(y=10x\).
Sol.
To plot these lines using GeoGebra, in the input bar at the bottom, type the equations and they will be plotted on the graph. Using GeoGebra to plot these lines provides a clear visual representation of how different linear equations with varying slopes behave. We can observe that the line $$y = 10x$$ is the steepest of them all. and the line $$y = x$$ is the shallowest.4.Observe that they all pass through the origin. Why?
Sol.
5.Plot \(y=2x+1\). Observe, Why doesn’t it pass through the origin?
Sol.
6.Plot \(y=ax+b\), with \(a\) and \(b\) as parameters which you should be able to vary. What do you observe?
Sol.
6(a). Let a line be \(y=5x+6\). For what values of \(\alpha\) and \(\beta\) will the line \(y= \alpha x + \beta\) be parallel to the given line? When will it intersect the given line in the 3rd quadrant?
Sol.
Two lines are only parallel if there slopes are equal. So for the line to be parallel to $$y = 5x + 6,$$ Alpha must be equal to 5, whereas the value of Beta does not change the lines being parallel. This can be observed by plotting the lines and using sliders on GeoGebra. For the lines to intersect in third quadrant, solve the two equations and when we will get the values of x and y in the terms of \(\alpha\) and \(\beta\), make both x and y less than 0. We will get the values of \(\alpha\) and \(\beta\) upon solving the inequalities.
7.Consider the following simultaneous equation:
\(2x+3y=7\)
\(3x+4y=10\)
Do you see a 2x2 matrix here? What is the importance of seeing a matrix in this problem? Why study matrices in general?
Do you observe that this problem can be retold as:
\(\left( \begin{matrix} 2 & 3 \\3 & 4 \\\end{matrix}\right)\)
\(\left(
\begin{matrix}
x\\
y\\
\end{matrix}
\right)\)
=\(\left(
\begin{matrix}
7\\
10\\
\end{matrix}
\right)\)
Sol.
8.Consider a simple function \(f(x) = 3x+2\). This function is invertible right? Can you tell us what is \(\alpha\) such that \(f(\alpha)=17\)? Is such an \(\alpha\) unique? How did you find such an \(\alpha?\). Is this always possible?
Sol.
An invertible function is one that has a unique inverse function, meaning that for every output value of the function, there is exactly one input value that produced it. This property ensures that each y in the function's range corresponds to exactly one x in the domain. So, yes, this function indeed is invertible. This equation can be solved by putting the value of the function as 17 in the equation and then solving it. The value of \(\alpha\) comes out to be 5. Linear functions with non-zero slopes are one-to-one (bijective) and thus have a unique inverse. For any given output y, there is exactly one input x such that f(x)=y. For such functions, it is always possible to find such a value.9.Consider the function \(f(x)=x^2-10\), what is \(f(5)\)?
Sol.
f(5) signifies the value of the function at \(x = 5\), which is given by \(x*x - 10\), i.e., \(25 - 10 = 15\).10.Consider the function \(f(x)=x^2-10\), if \(f(\alpha)=54\), what is \(\alpha\)?
Sol.
Here, we have to find x and we know the value of the function. So, \(54 = x*x - 10\), i.e., \(x = 8 or -8\).11.Consider the function \(g(x)=x^3-x^2-10x+2\), if \(g(x)=-22\) what is \(x\)?
Sol.
We can find this by plotting the curve of \(g(x) + 22 = 0\) on GeoGebra and then checking the roots of the equation.On plotting the curve, we observe that it has only one real root and two roots are imaginary as the degree of the equation is 3.
12.Do you know what is \(\mathbb{R}, \mathbb{R}^2 and\ \mathbb{R}^3\) ?
Sol.
13.Consider the function \(\phi : \mathbb{R}^2\rightarrow \mathbb{R}^2\) defined by \(\phi (x,y)=(2x+3y,3x+4y)\). Find x and y such that \(\phi (x,y)=(5,6)\). Obseve that (5,6) as well as (x,y) lies in \(\mathbb{R}^2\).
Sol.
To find the values of \(x\) and \(y\) such that the function \(\varphi: \mathbb{R}^2 \to \mathbb{R}^2\), defined by \(\varphi(x, y) = (2x + 3y, 3x + 4y)\), maps to the point \((5, 6)\), we need to solve the corresponding system of linear equations. Specifically, we set \(\varphi(x, y) = (5, 6)\), which gives us the system of equations: \[ 2x + 3y = 5 \] \[ 3x + 4y = 6 \] To solve this system, we can use the elimination method. First, we multiply the first equation by 3 and the second equation by 2 to align the coefficients of \(x\). This yields \[ 6x + 9y = 15 \] \[ 6x + 8y = 12 \] Next, we subtract the second equation from the first to eliminate \(x\), resulting in \[ 6x + 9y - 6x - 8y = 15 - 12 \] which simplifies to \[ y = 3 \] With \(y\) determined, we substitute \(y = 3\) back into one of the original equations to solve for \(x\). Using the first equation, \(2x + 3(3) = 5\), we get \[ 2x + 9 = 5 \] Subtracting 9 from both sides, we find \[ 2x = -4 \] and dividing by 2, we obtain \[ x = -2 \] Therefore, the values of \(x\) and \(y\) that satisfy \(\varphi(x, y) = (5, 6)\) are \(x = -2\) and \(y = 3\). It is important to observe that both the point \((5, 6)\) and the pair \((x, y)\) lie in \(\mathbb{R}^2\). This means that \((5, 6)\) and \((-2, 3)\) are both elements of the two-dimensional real number space, \(\mathbb{R}^2\), which is consistent with the domain and codomain of the function \(\varphi\).14.Is the function \(\phi\) invertible? In the question above on matrices, we see that it is of the form \(A\vec{x}=b\). Note that we can invert the matrix, using the method that was taught to us in our high school to find out the value for the variables \(x\) and \(y\). This is one of the many applications of matrices.
Sol.
To determine if the function \(\varphi\) is invertible, we need to analyze the function \(\varphi: \mathbb{R}^2 \to \mathbb{R}^2\) defined by \(\varphi(x, y) = (2x + 3y, 3x + 4y)\). This problem can be expressed in matrix form as \(A \vec{x} = \vec{b}\), where \(A\) is the matrix of coefficients, \(\vec{x}\) is the column vector of variables \((x, y)\), and \(\vec{b}\) is the result vector \((5, 6)\). The matrix \(A\) corresponding to the linear transformation is: \[ A = \begin{pmatrix} 2 & 3 \\ 3 & 4 \end{pmatrix} \] For \(\varphi\) to be invertible, the matrix \(A\) must be invertible. A matrix is invertible if its determinant is non-zero. We calculate the determinant of \(A\): \[ \det(A) = \begin{vmatrix} 2 & 3 \\ 3 & 4 \end{vmatrix} = (2 \cdot 4) - (3 \cdot 3) = 8 - 9 = -1 \] Since the determinant of \(A\) is \(-1\), which is non-zero, the matrix \(A\) is invertible. Consequently, the function \(\varphi\) is also invertible. To find the inverse function, we use the inverse of the matrix \(A\). The inverse of \(A\) is calculated using the formula for the inverse of a \(2 \times 2\) matrix: \[ A^{-1} = \frac{1}{\det(A)} \begin{pmatrix} d & -b \\ -c & a \end{pmatrix} = \frac{1}{-1} \begin{pmatrix} 4 & -3 \\ -3 & 2 \end{pmatrix} = \begin{pmatrix} -4 & 3 \\ 3 & -2 \end{pmatrix} \] Therefore, the inverse function \(\varphi^{-1}\) can be written as: \[ \varphi^{-1}(x', y') = \begin{pmatrix} -4 & 3 \\ 3 & -2 \end{pmatrix} \begin{pmatrix} x' \\ y' \end{pmatrix} = \begin{pmatrix} -4x' + 3y' \\ 3x' - 2y' \end{pmatrix} \] Applying this to find the values of \(x\) and \(y\) for \(\varphi(x, y) = (5, 6)\): \[ \begin{pmatrix} x \\ y \end{pmatrix} = \begin{pmatrix} -4 & 3 \\ 3 & -2 \end{pmatrix} \begin{pmatrix} 5 \\ 6 \end{pmatrix} = \begin{pmatrix} -4(5) + 3(6) \\ 3(5) - 2(6) \end{pmatrix} = \begin{pmatrix} -20 + 18 \\ 15 - 12 \end{pmatrix} = \begin{pmatrix} -2 \\ 3 \end{pmatrix} \] Thus, \(x = -2\) and \(y = 3\).14(a). Take a random looking 2*2 matrix. Is it invertible? How often is it invertible?
Sol.
To determine whether a random \(2 \times 2\) matrix is invertible, we need to consider the properties of the matrix. A \(2 \times 2\) matrix is invertible if and only if its determinant is non-zero. Let's take a random \(2 \times 2\) matrix: \[ A = \begin{pmatrix} a & b \\ c & d \end{pmatrix} \] The determinant of this matrix \(A\) is calculated as follows: \[ \det(A) = ad - bc \] For the matrix \(A\) to be invertible, \(\det(A)\) must not be equal to zero. Therefore, the condition for invertibility is: \[ ad - bc \neq 0 \]15.We will now see matrices as functions. Instead of \(\phi\) we will write the matrix itself:
\(\left( \begin{matrix} 2 & 3 \\3 & 4 \\\end{matrix}\right) : \mathbb{R}^2 \rightarrow \mathbb{R}^2\).
Sol.
We can view matrices as functions that map vectors from one space to another. For example, consider the matrix: \[ A = \begin{pmatrix} 2 & 3 \\ 3 & 4 \end{pmatrix} \] This matrix \(A\) can be seen as a function \(A: \mathbb{R}^2 \to \mathbb{R}^2\) that takes a vector from \(\mathbb{R}^2\) and maps it to another vector in \(\mathbb{R}^2\). Specifically, for a vector \(\vec{x} = \begin{pmatrix} x \\ y \end{pmatrix}\), the matrix function \(A\) acts on \(\vec{x}\) as follows: \[ A \vec{x} = \begin{pmatrix} 2 & 3 \\ 3 & 4 \end{pmatrix} \begin{pmatrix} x \\ y \end{pmatrix} = \begin{pmatrix} 2x + 3y \\ 3x + 4y \end{pmatrix} \]16.Consider the function \(\left( \begin{matrix} 1 & 2 \\2 & 4 \\\end{matrix}\right) : \mathbb{R}^2 \rightarrow \mathbb{R}^2\). This matrix takes a few elements to the origin. What are those elements? Plot this using Geogebra.
Sol.
Consider the function represented by the matrix \(A\): \[ A = \begin{pmatrix} 1 & 2 \\ 2 & 4 \end{pmatrix} \] This matrix \(A: \mathbb{R}^2 \to \mathbb{R}^2\) maps vectors from \(\mathbb{R}^2\) to \(\mathbb{R}^2\). We are interested in finding which vectors \(\vec{x} = \begin{pmatrix} x \\ y \end{pmatrix}\) are mapped to the origin by this matrix, i.e., we want to solve the equation: \[ A \vec{x} = \begin{pmatrix} 1 & 2 \\ 2 & 4 \end{pmatrix} \begin{pmatrix} x \\ y \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \end{pmatrix} \] This leads to the system of linear equations: \[ \begin{cases} 1x + 2y = 0 \\ 2x + 4y = 0 \end{cases} \] We can simplify this system by noting that the second equation is just twice the first equation. Therefore, it suffices to solve the first equation: \[ x + 2y = 0 \implies x = -2y \] This means that any vector of the form \(\vec{x} = \begin{pmatrix} -2y \\ y \end{pmatrix}\) will be mapped to the origin by the matrix \(A\). In other words, the vectors that are mapped to the origin lie along the line \(x = -2y\). This line will be called as the Null Space of the Matrix.Module B
17.\(A\) is assigned \(0\), \(B:1\), \(C:2\), and so on up to \(Z:25\)
Assume you denoted every letter with a number, as given in the table above.
You need to encrypt the word \(SUDARSHANA\) which stands for the numbers: \(18, 20, 3, 0, 17, 18, 7, 0, 13,0\).
You encrypt this using a matrix given by : \(\left( \begin{matrix} 2 & 3 \\3 & 4 \\\end{matrix}\right)\).
So \(SUDARSHANA\) will end up becoming: \(96, 134, 6, 9, 88, 123, 14, 21, 26, 39\).
Given these numbers, how will you decrypt the message and get back \(SUDARSHANA\)?
. This is a well known cryptographic protocol called the Hill Cipher. You can read more online.
Sol.
To decrypt the message encrypted using the Hill Cipher, we need to apply the inverse of the encryption matrix. Given the encrypted numbers representing "SUDARSHANA" as 96, 134, 6, 9, 88, 123, 14, 21, 26, and 39, we first identify the corresponding encryption matrix, denoted as \( \mathbf{E} \), which in this case is \( \begin{pmatrix} 2 & 3 \\ 3 & 4 \end{pmatrix} \). Utilizing this matrix, we compute its inverse, considering modulo 26 arithmetic. The decryption matrix, denoted as \( \mathbf{D} \), is then obtained. Proceeding with decryption, each pair of encrypted numbers undergoes matrix multiplication with \( \mathbf{D} \), followed by modulo 26 reduction. This process retrieves the original numbers corresponding to each letter. The decryption process is represented as \( \mathbf{p} = \mathbf{D} \cdot \mathbf{c} \pmod{26} \), where \( \mathbf{p} \) represents the decrypted numbers and \( \mathbf{c} \) represents the encrypted numbers. Finally, mapping these numbers back to their corresponding letters reveals the decrypted message "SUDARSHANA." This cryptographic protocol, known as the Hill Cipher, leverages linear algebra principles for both encryption and decryption, ensuring a secure communication channel.18.We encounter equations very often in our lives. Consider for example, the following situation at Baker’s Cafe. The manager has a very important estimate to make. Mostly, visitors at his cafe happen to be families and they are often comprised of Children and/or Adults. He observes that there are 3 adults and 1 child at a table and their bill turns out to be Rs.1200/-. There is yet another table with 2 children and 1 adult and their bill comes out to be Rs.1000/-. Can the manager estimate the consumption of a Child/Adult? This is popularly called the Simultaneous Equations and we all remember from our school days, multiple ways in which these can be solved.
\(3A + 1C = 1200\)
\(1A + 2C = 1000\)
Sol.
Let's denote the consumption of an adult as \(A\) and that of a child as \(C\). The first observation, with 3 adults and 1 child resulting in a bill of Rs. 1200, can be expressed as the equation: \[3A + 1C = 1200\]. Similarly, the second observation, with 2 children and 1 adult totaling Rs. 1000, can be represented as: \[1A + 2C = 1000\]. To solve this system of equations, we can employ various methods such as substitution, elimination, or matrix methods. The values of \(A\) and \(C\) are determined as \(280\) and \(360\) respectively.19.While we were taught the so called two variables and two unknowns, what if there were more equations than unknowns?
\(3A + 1C = 1200\)
\(1A + 2C = 1000\)
\(1A + 1C = 900\)
Sol.
Plot the three lines on 2-D plane. Observe that these do not have any unique solution. So, we cannot have any set of values of A and C which exactly fit in the 3 equations. Therefore, we will have to find the best fit, i.e., we have to find the values of A and C which make the outputs of all the three equations closest to their respective RHS. Think how can we approach this problem.20.Note that the previous question can be modelled as a matrix:
\(3A + 1C = 1200\)
\(1A + 2C = 1000\)
\(1A + 1C = 900\)
Observe this is same as :
\(\left( \begin{matrix} 3 & 1 \\1 & 2 \\1 & 1 \\\end{matrix}\right)\) \(\left( \begin{matrix} A\\ C\\ \end{matrix} \right)\) = \(\left( \begin{matrix} 1200\\ 1000\\ 900\\ \end{matrix} \right)\)
Now try to solve the previous problem.
Sol.
\[ \begin{pmatrix} 3 & 1 \\ 1 & 2 \\ 1 & 1 \\ \end{pmatrix} \begin{pmatrix} A \\ C \\ \end{pmatrix} = \begin{pmatrix} 1200 \\ 1000 \\ 900 \\ \end{pmatrix} \] Here, the coefficient matrix on the left represents the coefficients of the unknowns \(A\) and \(C\) in each equation, while the vector on the right represents the constants on the right-hand side of each equation. Observe that the LHS of the above equation can be written as \[ \begin{pmatrix} 3 \\ 1 \\ 1 \\ \end{pmatrix} A + \begin{pmatrix} 1 \\ 2 \\ 1 \\ \end{pmatrix} C = \begin{pmatrix} 1200 \\ 1000 \\ 900 \\ \end{pmatrix} \] Therefore, LHS can only be a linear combination of the vectors \((3,1,1)\) and \((1,2,1).\) But we need a vector which lies closest to our desired output, i.e., (1200,1000,900). So, we will see all the vectors which csn be formed by taking a linear combination of the 2 vectors. These all vectors lie on the plane formed by these vectors (Observe how?). Now we find the vector on this plane which is closest to the point in RHS. This will be obtained by taking the foot of perpendicular from the point (1200,100,900) on the plane. Now we have found the closest fit, which can be represented as a linear combination of the two vectors in LHS. Therefore, now we can find the values of A and C by solving any of the two equations, keeping the new point (closest one) in the RHS.21.One obvious way to solve this, is to guess the values :-). Can you get closer to the solution by guessing? Note that there is no solution to this question. You can just reduce the error. Do you see why?
Sol.
22.In the figure below:
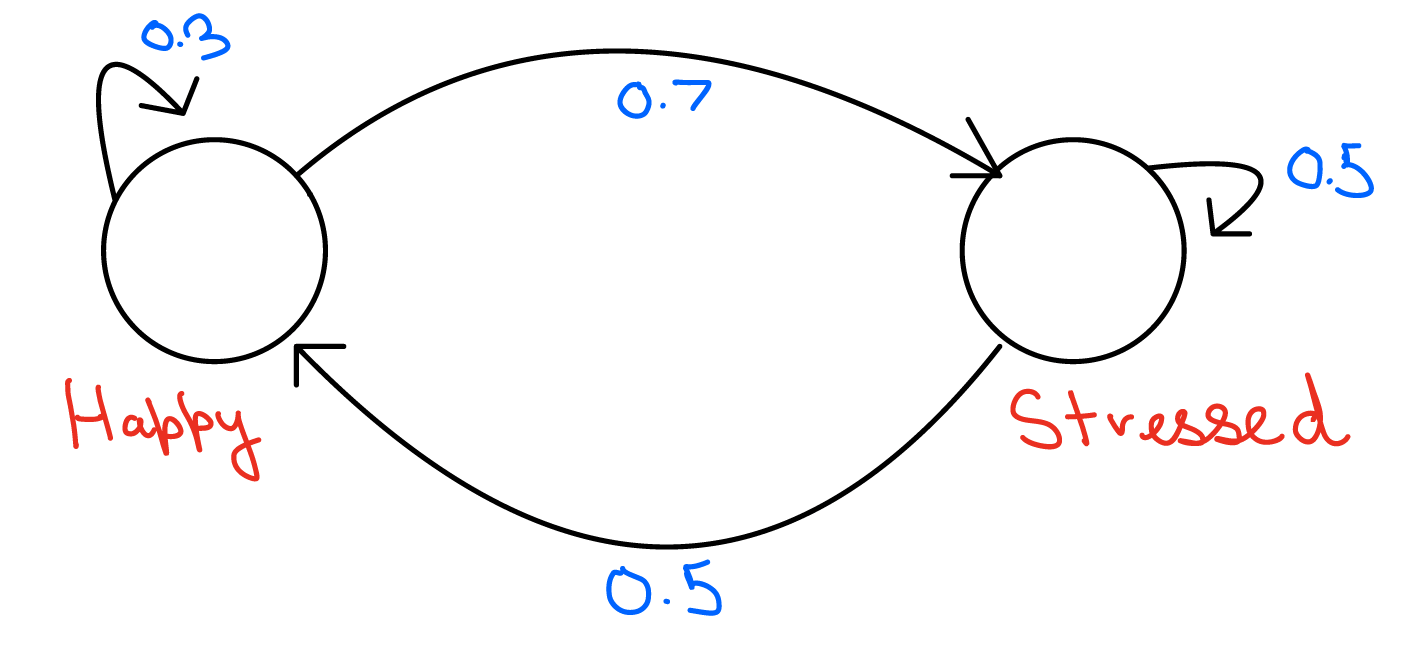 If 1000 people were to start in one state, what will be the distribution of people eventually? Write down a python script to find the convergence.
If 1000 people were to start in one state, what will be the distribution of people eventually? Write down a python script to find the convergence.
Sol.
To find the eventual distribution of people between the Happy (H) and Stressed (S) states, we can use the given system of equations and iterate until we reach convergence. The equations can be written in matrix form as: \[ \begin{pmatrix} H \\ S \end{pmatrix}_{n+1} = \begin{pmatrix} 0.3 & 0.5 \\ 0.7 & 0.5 \end{pmatrix} \begin{pmatrix} H \\ S \end{pmatrix}_{n} \] Let's denote the state vector as \( \mathbf{v} = \begin{pmatrix} H \\ S \end{pmatrix} \) and the transition matrix as \( A = \begin{pmatrix} 0.3 & 0.5 \\ 0.7 & 0.5 \end{pmatrix} \). The iteration process can be represented as: \[ \mathbf{v}_{n+1} = A \mathbf{v}_n \] We will use Python to perform this iteration and observe the convergence. Here's the script:import numpy as np
A = np.array([[0.3, 0.5],[0.7, 0.5]])
v = np.array([1000, 0])
def iterate_until_convergence(A, v, tolerance=1e-6, max_iterations=10000):
for _ in range(max_iterations):
v_next = A @ v
if np.allclose(v, v_next, atol=tolerance):
return v_next
v = v_next
return v
final_distribution = iterate_until_convergence(A, v)
total_population = np.sum(final_distribution)
percentage_distribution = final_distribution / total_population * 100
print(final_distribution, percentage_distribution)
23.In the figure below:
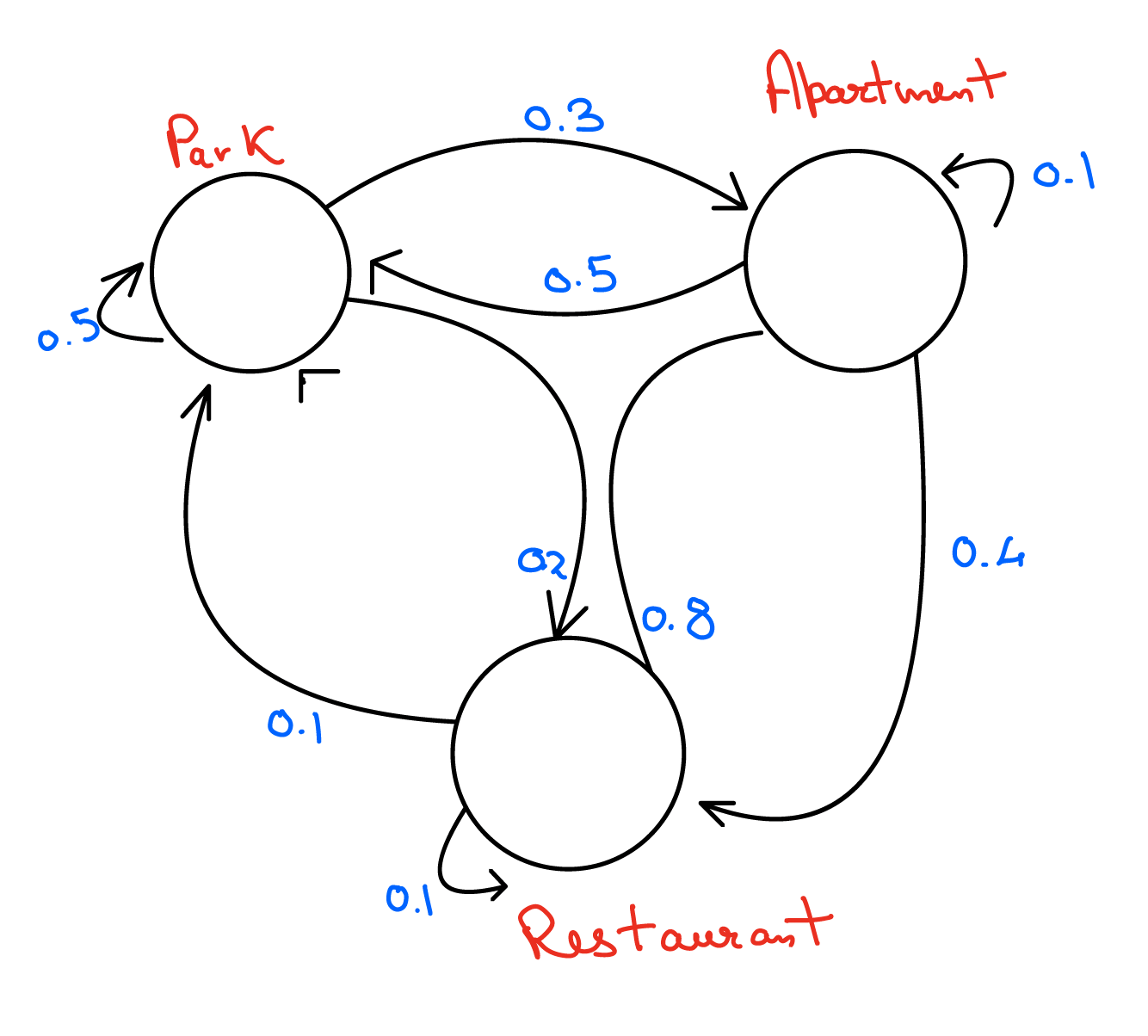 If 1000 people were to start in one state, what will be the distribution of people eventually? Write down a python script to find the convergence.
If 1000 people were to start in one state, what will be the distribution of people eventually? Write down a python script to find the convergence.
Sol.
This question will be solved similar to the previous one. But, the Matrix equation will be as follow: \[ \begin{pmatrix} P \\ A \\ R \\ \end{pmatrix}_{n+1} = \begin{pmatrix} 0.5 & 0.5 & 0.1 \\ 0.3 & 0.1 & 0.8 \\ 0.2 & 0.4 & 0.1 \\ \end{pmatrix} \begin{pmatrix} P \\ A \\ R \\ \end{pmatrix}_{n} \]Module C
24.Use Geogebra: Draw the vector \(\begin{bmatrix}1 \\ 1 \\ \end{bmatrix}\). Find out all those vectors which are perpendicular to this vector.
Sol.
The given vector can be drawn with the help of the vector tool in GeoGebra. All the vectors which have their dot product with the given vector as 0 will be orthogonal to it. They will be of the form: $$v = (t, -t),$$ where t is an arbitrary variable.25.Do you observe that we are asking for vectors \(\begin{bmatrix}x \\ y \\ \end{bmatrix}\) such that, \(\begin{bmatrix}1 & 1 \\ \end{bmatrix} \begin{bmatrix} x\\ y \\ \end{bmatrix}=0\)
Sol.
The given set of matrices lead to the equation which we get while doing the dot of these vectors as 0, i.e., $$x + y = 0$$ So, This equation represents all the vectors perpendicular to the given one. These vectors lie along the line with slope -1 passing through the origin in the Cartesian coordinate system.26.Use Geogebra and solve the above question with \(\begin{bmatrix} 1 \\ 1 \\ \end{bmatrix}\) replaced by \(\begin{bmatrix}a \\ b \\ \end{bmatrix}\).Use \((a,b)\) as parameters and check what happens to \((x,y)\).
Sol.
As a consequence of this change, the straight line will become: $$ ax + by = 0$$ This will only change the corresponding slope, i.e., the vectors will lie on the line passing through the origin with the slope equal to -a/b.27.What is \((x,y,z)\) satisfying the following equation? (Use Geogebra) \(\begin{bmatrix}1 & 2 & 3\\ \end{bmatrix} \begin{bmatrix} x\\ y \\ z\\ \end{bmatrix}=0\)
Sol.
The equation given is \( [123]\begin{bmatrix} x \\ y \\ z \end{bmatrix} = 0 \). To solve this, we can multiply the matrix \( [123] \) by the column vector \( \begin{bmatrix} x \\ y \\ z \end{bmatrix} \) using matrix multiplication. \[ \begin{bmatrix} 1 & 2 & 3 \\ \end{bmatrix} \begin{bmatrix} x \\ y \\ z \end{bmatrix} = \begin{bmatrix} 1x + 2y + 3z \\ \end{bmatrix} = 0 \] For the equation to hold true, the result of this multiplication must be zero. Therefore, the solution to the equation is any vector \( \begin{bmatrix} x \\ y \\ z \end{bmatrix} \) such that \( x + 2y + 3z = 0 \). We will now go plot the equation on GeoGebra. We observe that this represents an equation of a plane and it contains the collection of position vectors which satisfy the given equation.28.Use Geogebra and plot all the points in the set below. \(T= \{ \alpha(1,2,1) | \alpha \in \mathbb{R}\}\)
Sol.
To plot all the points, we will create the given vector in the graph. Then we will use the sequence command in desired range to show the possible vectors under the given expression as in the question. We observe that the points follow a straight line pattern passing through the Origin.29.Use Geogebra and plot all the points in the set below. \(S= \{ \beta(2,7,3) | \beta \in \mathbb{R}\}\)
Sol.
The question will be solved exactly similar to the previous one.30.Use Geogebra and plot all the points in the set below. \(W= \{\alpha(1,2,1) + \beta(2,7,3) | \alpha,\beta \in \mathbb{R}\}\)
Sol.
We can simply add the two previous sets to create the third one as given in the question in GeoGebra.31.In the above set \(W\) find out all the points \((x,y,z)\) satisfying the following: (Use Geogebra) \(\begin{bmatrix}w_1 & w_2 & w_3\\ \end{bmatrix} \begin{bmatrix} x\\ y \\ z\\ \end{bmatrix}=0\) where \((w_1,w_2,w_3) \in W\). Note that \(w_i\)s are real numbers.
Sol.
32.Given the matrix \(A=\begin{bmatrix}1 & 2 & 3\\ 4 & 5 &6\\ 7 & 8 & 9\\ \end{bmatrix}\), find out all the possible \((x,y,z)\) such that: \(\begin{bmatrix}1 & 2 & 3\\ 4 & 5 &6\\ 7 & 8 & 9\\ \end{bmatrix} \begin{bmatrix} x\\ y\\ z\\ \end{bmatrix}=0\) Observe carefully, what has this question got to do with previous five questions in this module
Sol.
Given the matrix \( A = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix} \), we need to find out all the possible \( (x, y, z) \) such that: \[ A \begin{bmatrix} x \\ y \\ z \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix} \]This represents a homogeneous system of linear equations. To find the solution, we need to determine the null space (kernel) of matrix \( A \). Let's write down the system of equations: \[ \begin{cases} 1x + 2y + 3z = 0 \\ 4x + 5y + 6z = 0 \\ 7x + 8y + 9z = 0 \end{cases} \] Therefore, the solution to the system is: \[ \begin{bmatrix} x \\ y \\ z \end{bmatrix} = \begin{bmatrix} t \\ -2t \\ t \end{bmatrix} = t \begin{bmatrix} 1 \\ -2 \\ 1 \end{bmatrix} \]
where \( t \) is any real number. The solution set is: \[ \{(t, -2t, t) \mid t \in \mathbb{R}\} \]
This means all points \((x, y, z)\) lie on the line parametrized by \((t, -2t, t)\).
33.Given the matrix \(A=\begin{bmatrix}1 & 2 & 3\\ 4 & 5 &6\\ 7 & 8 & 9\\ \end{bmatrix}\) what does the following three sets represent?
(i) \(\mathscr{R}=\{\alpha(1,2,3) + \beta(4,5,6) + \gamma(7,8,9) |\alpha, \beta, \gamma\in \mathbb{R}\}\)
(ii) \(C=\{\alpha(1,4,7) + \beta(2,5,8) + \gamma(3,6,9) | \alpha, \beta, \gamma \in \mathbb{R}\}\)
(iii) \(N=\{(x,y,z)|x(1,4,7) + y(2,5,8) + z(3,6,9) = 0 \}\)
Use only Geogebra :)
Sol.
34.Did you observe that every vector of \(\mathscr{R}\) is perpendicular to every vector of \(N\)?
Sol.
This observation can easily be made once the graphs are plotted in GeoGebra.35.Consider the matrix \(B=\begin{bmatrix} 1 & 2 \\ 2 & 4\\ \end{bmatrix}\). Draw the line \(2y+x=4\). Seeing the matrix \(B\) as a function \(B:\mathbb{R^2}\mapsto \mathbb{R^2}\),
where does \(B\) takes the line \(2y+x=4\)?
Where does it take:
i)\(2y+x=10\)
ii)\(2y+x=62\)
iii)\(2y+x=1800\)
Sol.
For \(x + 2y = 4\), \[ B \begin{pmatrix} x \\ y \end{pmatrix} = \begin{pmatrix} 1 & 2 \\ 2 & 4 \end{pmatrix} \begin{pmatrix} x \\ -\frac{1}{2}x + 2 \end{pmatrix} = \begin{pmatrix} x + 2\left(-\frac{1}{2}x + 2\right) \\ 2x + 4\left(-\frac{1}{2}x + 2\right) \end{pmatrix} \]Simplifying, we get: \[ \begin{pmatrix} x + 2(2 - \frac{1}{2}x) \\ 2x + 4(2 - \frac{1}{2}x) \end{pmatrix} = \begin{pmatrix} 4 \\ 8 \end{pmatrix} \]
So, every point lying on the line \(x + 2y = 4\) is transformed to the point \((4,8)\) by the matrix B.
Now, let's compute the transformations for each specific case: (i) For the line \(2y + x = 10\), we rewrite it as \(y = -\frac{1}{2}x + 5\).
Approaching with the similar method, we get that every point here is directed towards \((10,20)\)
(ii) For the line \(2y + x = 62\), we rewrite it as \(y = -\frac{1}{2}x + 31\).
Applying the transformation \(B\) to this line, we'll follow the same steps as above.
(iii) For the line \(2y + x = 1800\), we rewrite it as \(y = -\frac{1}{2}x + 900\).
Applying the transformation \(B\) to this line, we'll follow the same steps as above.
35(a).In general \(B=\begin{bmatrix} 1 & 2 \\ 2 & 4\\ \end{bmatrix}:\mathbb{R^2}\mapsto \mathbb{R^2}\), where does this function take \(2y+x=k\)?(where \(k\) is a constant)
Sol.
Following the same procedure, we get that the points on such a line when undergo transformation through the matrix B, all lead to a point, i.e., \((k,2k)\).36.Consider a matrix \(A=\begin{bmatrix} 1 & 4 \\ 2 & 3\\ \end{bmatrix}\) and a vector $v$ = \(\begin{bmatrix} 1 \\ 1\\ \end{bmatrix}\) to what is it transformed?
36(a).Is it rotated?
36(b).Is the magnitude preserved?
36(c).What is the ratio of magnitude of \(Av\) to \(v\)?
Sol.
To transform the vector \( v \) using the matrix \( A \), we perform matrix multiplication:\[ Av = \begin{bmatrix} 1 & 4 \\ 2 & 3 \end{bmatrix} \begin{bmatrix} 1 \\ 1 \end{bmatrix} \] \[ Av = \begin{bmatrix} 1*1 + 4*1 \\ 2*1 + 3*1 \end{bmatrix} \] \[ Av = \begin{bmatrix} 1 + 4 \\ 2 + 3 \end{bmatrix} = \begin{bmatrix} 5 \\ 5 \end{bmatrix} \]
So, the vector \( v \) is transformed to \( Av = \begin{bmatrix} 5 \\ 5 \end{bmatrix} \).
\((A)\) No, it is not rotated. A rotation would imply a change in direction, but here, the direction of the vector remains the same after transformation.
\((B)\) No, the magnitude is not preserved. The original vector \( v \) had a magnitude of \( \sqrt{1^2 + 1^2} = \sqrt{2} \), while the transformed vector \( Av \) has a magnitude of \( \sqrt{5^2 + 5^2} = \sqrt{50} \), which is larger.
\((C)\) The magnitude of \( Av \) is \( \sqrt{50} \), and the magnitude of \( v \) is \( \sqrt{2} \). So, the ratio is:
\[ \frac{\|Av\|}{\|v\|} = \frac{\sqrt{50}}{\sqrt{2}} = \sqrt{\frac{25}{1}} = 5 \]
So, the ratio of the magnitude of \( Av \) to \( v \) is 5.
37.Given \(B=\begin{bmatrix} 1 & 2 \\ 2 & 4\\ \end{bmatrix}:\mathbb{R^2}\mapsto \mathbb{R^2}\). What is the range of this function?
Sol.
The range of this function is a straight line pasing through the Origin with slope equal to 2, i.e., \(y = 2x\).38.You have achieved the required wisdom if you have realized that:
\(B=\begin{bmatrix} 1 & 2 \\ 2 & 4\\ \end{bmatrix}:\mathbb{R^2}\mapsto \mathbb{R^2}\).
“ \(B\) collapses a dimension “.
Sol.
Indeed, the matrix \( B = \begin{pmatrix} 1 & 2 \\ 2 & 4 \end{pmatrix} \) represents a transformation that collapses a dimension. This can be inferred from the fact that the range of the transformation is a straight line in \( \mathbb{R}^2 \). In other words, applying the transformation \( B \) to any input vector in \( \mathbb{R}^2 \) results in an output vector lying along a one-dimensional subspace of \( \mathbb{R}^2 \).This collapse of dimensionality is evident in the transformation because the second row of the matrix \( B \) is a scalar multiple of the first row, indicating that the transformation essentially scales one dimension (the \( y \)-dimension) by a factor of 2 relative to the other dimension (the \( x \)-dimension), ultimately resulting in a line where the two dimensions are equal.
Module D
39.Given the matrix \(M=\begin{bmatrix} 1 & 3 \\ 2 & 6\\ \end{bmatrix}\). Use Geogebra to plot \(\mathscr{R}\), \(\mathscr{C}\) & \(\mathscr{N}\). what do you observe?
(i) \(\mathscr{R}=\{\alpha(1,3) + \beta(2,6) | \alpha, \beta\in \mathbb{R}\}\)
(ii) \(\mathscr{C}=\{\alpha(1,2) + \beta(3,6) | \alpha, \beta\in \mathbb{R}\}\)
(iii) \(\mathscr{N}=\{(x,y)| x(1,3) + y(2,6) = 0, \forall x,y\in \mathbb{R} \}\)
Sol.
\((A)\) Upon plotting these graphs on Geogebra, we observe that the set R, which shows the possible combinations of the rows of matrix M, leads to set of points which lie on a straight line, which can be plotted with the help of in built functions provided..
\((B)\) Similarly, the set C, that signifies the possible combinations of the columns of the matrix M, plots the points, lying on another straight line, on an angle to the previous one.
\((C)\) The set N represents the solutions to a specific equation involving the rows and columns of M. It also forms a straight line on the graph, starting from the origin and having a different orientation compared to R and C.
This observation clarifies the visual representation of the relations between rows, columns and their combinations.40.Note that \(\mathscr{C}\) and \(\mathscr{N}\) are orthogonal.
Sol.
We observed in the previous question that the points on both C and N follow a straight line path. When we plot the straight line on the graph with the function using origin as the point and our vector as defined in the question, we get the lines as $$y = 2x$$ and $$x = -2y.$$ Here, we can observe from both the equations and also by looking at the graph itself that the two lines come out to be perpendicular to each other.41.What is the null-space of \(M=\begin{bmatrix} 1 & 3 \\ 2 & 6\\ \end{bmatrix}\) & the null-space of \(M^T\)?
Sol.
Null Space of a Matrix is defined as the set of points such that their column matrix X when post multiplied by the matrix M itself produces the Null Matrix O of relevant order, i.e., $$MX = O.$$ When we multiply these matrices, we get two equations in two variables. $$x + 3y = 0$$ $$2x + 6y = 0$$ We can observe that the two equations are same and the solution for the null space of the matrix comes out to be the straight line from the equation, i.e., $$x = -3y.$$ Similarly, we can do it for the transpose matrix of M. Let the transpose matrix of M be N. Now, as we learnt earlier, Null space of N will be found by the following equation: $$NX = O$$ This leads us to the equations: $$x + 2y = 0$$ $$3x + 6y = 0$$ Similar to the previous example, the solution for the null space for N, the transpose of the matrix M, comes out to be a straight line, $$x = -2y.$$42.Do you observe that \(C(M)\) ⊥ \(N(M^T)\) , \(R(M)\) ⊥ \(N(M)\) ?
Sol.
This observation can easily be made by plotting the two graphs on Geogebra.43.Consider \(A=\begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \\ \end{bmatrix}\). What is \(N(A)\), \(C(A)\), \(R(A)\), \(N(A^T)\).
Sol.
Let us first check the Null Space. As the square matrix used is of the order of 3 now, not of the order of 2, we will have three equations in 3 variables. But the basic approach for Null Space will be the same, i.e., $$AX = O.$$ We will get the following equations: $$x + 2y + 3z = 0$$ $$4x + 5y + 6z = 0$$ $$7x + 8y + 9z = 0$$ We can use Geogebra to solve these equations. We get the solution as: $$x = - y/2 = z,$$ which is the null space of the provided matrix. Similarly, for the transpose of the provided matrix, we will get the following equations: $$x + 4y + 7z = 0$$ $$2x + 5y + 8z = 0$$ $$3x + 6y + 9z = 0$$ We get the solution as: $$x = -y/2 = z,$$ which, we can observe, is exactly similar to the Null Space of A itself. Now, we will check the Column Space of the given matrix. We have seen how $C(M)$ is defined previously in this module. Going with the similar approach, we get the set C(A) as: $$C(A) = \{a(1,4,7) + b(2,5,8) + c(3,6,9) : a, b, c \text{ belong to \} R}$$ Similarly, $$R(A) = \{a(1,2,3) + b(4,5,6) + c(7,8,9) : a, b, c \text{ belong to \} R}$$44.Consider a 4x4 matrix \(M\): \(\mathbb{R^4}\mapsto \mathbb{R^4}\) whose range is
a) \(4-Dimension\)
b) \(3-Dimension\)
c) \(2-Dimension\)
d) \(1-Dimension\)
e) \(0-Dimension\)
Give an example each for all the above 5 cases.
Sol.
(a) \( A=\begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix} \)(b) \( A=\begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix} \)
(c) \( A=\begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix} \)
(d) \( A=\begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix} \)
(e) \( A=\begin{bmatrix} 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix} \)
Note that any other example which satisfies the given condition is also a correct answer for the question.
45.Consider \(A : \mathbb{R^{3}} \to \mathbb{R^{3}}\)
a) Show that if the range contains a point \((a,b,c)\), then it should contain the entire set \(S\), defined by:
\(S= \{\alpha(a, b,c)| \alpha \in \mathbb{R}\}\).
b) Show that if the range contains the points \((a,b,c)\) and \((d,e,f)\), then the range contains the entire set \(T\) defined by:
\(T=\{\alpha(a,b,c) + \beta(d,e,f) \thinspace|\thinspace \alpha,\beta\in \mathbb{R}\}\).
c) Note: \(S\) is of the dimension \(1\), but \(T\) need’nt be of dimension \(2\). Think!
Sol.
Module E
46.Give an example of two \(2-dim\) subspaces in \(\mathbb{R^{3}}\). Let us call it \(S_1, S_2\).
Sol.
To provide an example of two 2 - dimensional subspaces in 3 - dimensional Real space, we need to define two different planes through the origin in the whole space. For example, they can be the xy and the zx - planes. Therefore, $$S_1 = \{(x,y,0) : x,y \text{ belong to } R\}$$ $$S_2 = \{(x,0,z) : x,z \text{ belong to } R\}$$47.Let \(S_3\) be all those vectors perpendicular to \(S_1\). \(S_4\) be that of \(S_2\).
Sol.
48.Find a matrix \(M\) whose Null-Space is \(S_3\). column space is \(S_2\).
Sol.
$$ A=\begin{bmatrix} 1 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 1 & 0 \\ \end{bmatrix}$$ As we know that row space and null space of a matrix are orthogonal to each other. It can clearly be observed from this matrix that its row space is xy plane and hence, as z - axis is orthogonal to it, it is its null space.49.What does \(S_1\) and \(S_4\) represent?
Sol.
50.Do you observe there is a bijection from \(S_1 \to S_2\)?
Sol.
Module F
51.Imagine a situation of war in 1800’s.Country A wants to send a letter to Country B such that their enemy country can’t understand the message.How can you help the country A in this situation?
Sol.
In the scenario of wartime communication in the 1800s, Country A could employ the Caesar cipher to encode their messages to Country B. The Caesar cipher is a substitution cipher where each letter in the plaintext is shifted a certain number of places down or up the alphabet. By agreeing on a specific shift value beforehand, known as the "key," Country A could encode their messages, making them unintelligible to their adversaries without the knowledge of the key. In the Caesar cipher, each letter in the plaintext is shifted by a fixed number of positions in the alphabet. Mathematically, this can be represented using modular arithmetic. Let's denote \( n \) as the shift value (the key) and \( P \) as the position of a letter in the alphabet. The Caesar cipher encryption function \( E \) can be expressed as: \[ E(P) = (P + n) \mod 26 \] Where \( \mod 26 \) ensures that the result wraps around the alphabet. For example, if \( n = 3 \) and \( P = 1 \) (representing 'A'), the encrypted letter would be \( E(1) = (1 + 3) \mod 26 = 4 \), which corresponds to 'D'.
52.How about shifting the alphabets by 1 letter each?What is the problem here?
Sol.
Shifting each letter of the alphabet by one position, known as a Caesar cipher with a fixed key of 1, is a simple form of substitution cipher. While it provides a basic level of encryption, it suffers from a significant vulnerability: its lack of security due to its limited key space. Since there are only 25 possible keys (each shift value from 1 to 25), an attacker can easily perform a brute-force attack by trying all possible keys to decrypt the message. This means that the encrypted message can be deciphered through only 25 trials, making it highly vulnerable to cryptanalysis.
53.Try encoding the word “VICHARANASHALA” using the above method (But shift 4 letters this time)
Sol.
To encode the word "VICHARANASHALA" using a Caesar cipher with a shift of 4 letters, we shift each letter in the word by four positions in the alphabet: - V becomes Z - I becomes M - C becomes G - H becomes L - A becomes E - R becomes V - A becomes E - N becomes R - A becomes E - S becomes W - H becomes L - A becomes E - L becomes P - A becomes E So, "VICHARANASHALA" would be encoded as "ZMGLEREVREWEP".
54.What if you have only the encoded message? How will you get to the original message?
Sol.
If we only have the encoded message and no knowledge of the key (the shift value used in the Caesar cipher), we would need to employ cryptanalysis techniques to decrypt the message. One common approach is frequency analysis, which relies on the fact that certain letters appear more frequently than others in natural language text. For example, in English, the most common letters are 'E', 'T', 'A', 'O', and 'I'. By analyzing the frequency of letters in the encoded message and comparing it to the expected frequency distribution of letters in English text, we can make educated guesses about the shift value. Another method involves trying all possible shift values (from 1 to 25) and examining the decrypted text for meaningful words or patterns. This brute-force approach would involve decoding the message 25 times with different shift values until the original message is revealed.
55.What if we substitute each letter by some other letter using a pre- defined mapping (eg.a->t,b->f,c->y,…)?How many trails do we have to do so that we can reach the secret message if we only have the encoded text and not the mapping ?
Sol.
If we have an encoded message using a substitution cipher with a predefined mapping, and we don't know the mapping, we essentially face a cryptanalysis problem. The number of possible mappings in a substitution cipher depends on the size of the alphabet used in the encoding. For example, if we're using the English alphabet, which consists of 26 letters, there are \( 26! \) possible permutations of the alphabet. Therefore, without knowing the mapping, we would need to try each possible permutation to decipher the message. This brute-force approach would require checking all \( 26! \) mappings, which is clearly impractical due to the vast number of trials involved. In summary, if we only have the encoded text and not the mapping used in a substitution cipher, it is practically infeasible to decipher the secret message by trying all possible mappings.
56.Is there any efficient approach for the second part of the 55th question?
Sol.
Yes, there are more efficient approaches for decrypting a message encoded with a substitution cipher when the mapping is unknown. One common technique is frequency analysis. In most languages, including English, certain letters occur more frequently than others. Here's how frequency analysis works: 1. Count the frequency of each letter in the encoded message. 2. Compare the frequency distribution to the expected frequency distribution of letters in the language being used (e.g., English). 3. Identify common patterns, such as single-letter words or repeated sequences, which may correspond to common letters or words in the language. 4. Use these patterns to make educated guesses about the mapping, such as which encoded letter corresponds to 'E' or 'T'. 5. Once a few letters are deciphered, use context and word patterns to further decrypt the message.
57.What do you think is the frequency of occurence of various letters in a sample English text? Which letter do you expect to be the most frequent ?
Sol.
In a typical English text, the frequency of occurrence of various letters follows a well-known distribution. The most frequent letter in English text is 'E', followed by 'T', 'A', 'O', 'I', 'N', 'S', 'H', 'R', 'D', 'L', 'C', 'U', 'M', 'W', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', 'J', 'X', 'Q', and 'Z', in descending order of frequency. These frequencies can vary slightly depending on the specific text and context, but they provide a general guideline for the relative occurrence of letters in English text.
58.Assuming that an English text follows a particular order of frequency,can you solve the 56th question?
Sol.
Assuming that the English text follows the typical order of letter frequency, we can use this knowledge to help decrypt a message encoded with a substitution cipher. Given the encoded message, we can analyze the frequency of letters in the text. By identifying the most frequently occurring letter in the encoded message, we can make an educated guess that it corresponds to the most frequent letter in English text, which is 'E'. Once we determine the mapping for this letter, we can continue deciphering the rest of the message based on context and patterns. This process can be iterated, gradually revealing more letters and improving our understanding of the mapping until the entire message is decrypted. While frequency analysis provides a powerful tool for decrypting substitution ciphers, it may still require some manual effort and linguistic knowledge, especially for longer messages or messages with less predictable patterns. However, by leveraging the knowledge of letter frequency in English text, we can significantly reduce the number of trials needed to decrypt the message compared to a brute-force approach.
59.Suppose we take a subset from a huge text i.e \(k^{th}\), \(2k^{th}\), \(3k^{th}\)… elements.Will they also follow the same pattern observed in the previous question?
Sol.
Yes, if we take a subset of characters from a large enough English text, such as every \(k^{th}\) character, \(2k^{th}\) character, \(3k^{th}\) character, and so on, they are likely to follow a similar pattern of letter frequency as observed in the previous question. This is because the frequency distribution of letters in English text is relatively stable across different texts, assuming the text samples are large enough and representative of typical English language usage. Therefore, even when considering a subset of characters from a large text, we would still expect the most frequent letters to be 'E', 'T', 'A', 'O', 'I', and so on, in roughly the same order of frequency. Of course, the specific frequencies may vary slightly depending on the particular text and context, but the overall pattern of letter frequency should remain consistent. This consistency is what allows frequency analysis to be an effective technique for decrypting substitution ciphers, even when working with subsets of text.
60.Assume you arrange two meaningful english text strings in front of each other. What is the expected number of collisions in the letters? Call it “collision frequency”.
Sol.
To calculate the expected number of collisions in the letters of two meaningful English text strings arranged in front of each other, we follow these steps:1. Frequency Distribution: Define the frequency distribution of characters in English text. Denote the probability of occurrence of each character as \( p \), where \( i \) ranges from 1 to \( N \), the total number of characters in the English alphabet.
2. Collision Probability for Each Character: Calculate the collision probability for each character, denoted as \( P_{\text{collision}, i} \). This can be calculated as the square of the probability of occurrence of that character: \( p_i^2 \).
3. Collision Frequency: The expected number of collisions in a position is the sum of the collision probabilities for all characters. Denote the collision frequency as \( \text{collision frequency} \), which can be calculated as the sum of \( P_{\text{collision}, i} \) over all characters: \[ \text{collision frequency} = \sum_{i=1}^{N} p_i^2 \] Total Number of Collisions = N * Collision frequency.
61.Assume that in the previous question ,we apply the ceaser cypher(the one discussed in the first few questions), on both the strings, and alphabet by 5 letters then will the collision frequency remain the same?What if we shift first string by 3 letters and second by 5?
Sol.
Applying the Caesar cipher to both strings by shifting each letter by the same amount will not change the collision frequency. This is because the relative positions of the characters within each string remain the same, only their actual representations change.However, if we shift the first string by a different amount than the second string, it will affect the collision frequency. This is because the relative positions of characters within each string will change, leading to a different distribution of characters and hence a different collision frequency.
62.Suggest any such method using which we can be confident that the encoded text can’t be decoded by the enemy. (We may discuss it in further classes)
Sol.
Project 1- Vigenere Cipher
Module G
63.A dart is thrown at random onto a board that has the shape of a circle as shown below. Calculate the probability that the dart will hit the shaded region.
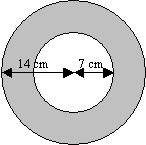
Sol.
The shaded region is the difference in area between two concentric circles (a larger circle and a smaller circle). - The radius of the larger circle \( R \) is 14 units. - The radius of the smaller circle \( r \) is 7 units. The area of the shaded region \( A_{\text{shaded}} \) is given by the difference in the areas of these two circles: \[ A_{\text{shaded}} = \pi R^2 - \pi r^2 \] Substituting the values: \[ A_{\text{shaded}} = \pi (14^2 - 7^2) \] \[ A_{\text{shaded}} = \pi (196 - 49) \] \[ A_{\text{shaded}} = \pi \cdot 147 \] The total area \( A_{\text{total}} \) is the area of the larger circle: \[ A_{\text{total}} = \pi R^2 \] Substituting the value: \[ A_{\text{total}} = \pi \cdot 14^2 \] \[ A_{\text{total}} = \pi \cdot 196 \] The probability \( P \) of a dart hitting the shaded region is the ratio of the area of the shaded region to the total area of the circle: \[ P = \frac{A_{\text{shaded}}}{A_{\text{total}}} \] Substituting the areas calculated: \[ P = \frac{\pi \cdot 147}{\pi \cdot 196} \] \[ P = \frac{147}{196} \] Simplifying the fraction: \[ P = \frac{147 \div 49}{196 \div 49} \] \[ P = \frac{3}{4} \] Thus, the probability of a dart hitting the shaded region is \( \frac{3}{4} \) or 0.75.64.Let a pair of dice be thrown and the random variable X be the sum of the numbers that appear on the two dice. Find the mean or expectation of X.
Sol.
To find the mean or expectation of the random variable X, which represents the sum of the numbers on two dice, you can use the formula: \[ \text{Mean} (\mu) = \sum_{i=2}^{12} i \times P(X=i) \] Where \( P(X=i) \) is the probability that the sum of the two dice equals \( i \). The sum can range from 2 (if both dice show 1) to 12 (if both dice show 6). The probability of getting each sum can be calculated by considering all possible combinations of the dice. Here's a table of the sums and their probabilities: \[ \begin{array}{|c|c|} \hline \text{Sum} & \text{Probability} \\ \hline 2 & \frac{1}{36} \\ 3 & \frac{2}{36} \\ 4 & \frac{3}{36} \\ 5 & \frac{4}{36} \\ 6 & \frac{5}{36} \\ 7 & \frac{6}{36} \\ 8 & \frac{5}{36} \\ 9 & \frac{4}{36} \\ 10 & \frac{3}{36} \\ 11 & \frac{2}{36} \\ 12 & \frac{1}{36} \\ \hline \end{array} \] Now, calculate the mean: \[ \mu = (2 \times \frac{1}{36}) + (3 \times \frac{2}{36}) + (4 \times \frac{3}{36}) + \ldots + (12 \times \frac{1}{36}) \] \[ \mu = \frac{2}{36} + \frac{6}{36} + \frac{12}{36} + \ldots + \frac{12}{36} \] \[ \mu = \frac{1}{36} \left(2 + 6 + 12 + \ldots + 12 \right) \] \[ \mu = \frac{1}{36} \times (252) \] \[ \mu = \frac{1}{36} \times 252 \] \[ \mu = \frac{252}{36} \] \[ \mu = 7 \] So, the mean or expectation of \( X \) is approximately \( 7 \).
65.A factory produces items, and each item is independently defective with probability
0.2. If 100 items are produced in a day, what is the expected number of defective items?
Sol.
To find the expected number of defective items produced in a day by the factory, we use the concept of expectation in probability theory. Given: - Each item is defective with probability \( p = 0.2 \). - The number of items produced in a day \( n = 100 \). The expected number of defective items \( E(X) \) can be calculated using the formula for the expectation of a binomial distribution: \[ E(X) = n \cdot p \] Substituting the given values: \[ E(X) = 100 \cdot 0.2 \] \[ E(X) = 20 \] Thus, the expected number of defective items produced in a day is 20.
66.A point is chosen at random inside a sphere of radius R. What is the probability that this point is closer to the center of the sphere than to its surface?
Sol.
To find the probability that a randomly chosen point inside a sphere is closer to the center than to its surface, we analyze the problem geometrically. Given: - The sphere has a radius \( R \). - We need to find the probability that a point is closer to the center than to the surface of the sphere. - A point inside the sphere is closer to the center than to the surface if its distance from the center is less than half the radius of the sphere, \( \frac{R}{2} \). The volume \( V_{\text{inner}} \) of the sphere with radius \( \frac{R}{2} \) is given by: \[ V_{\text{inner}} = \frac{4}{3} \pi \left( \frac{R}{2} \right)^3 = \frac{4}{3} \pi \cdot \frac{R^3}{8} = \frac{1}{6} \pi R^3 \] The volume \( V_{\text{total}} \) of the sphere with radius \( R \) is given by: \[ V_{\text{total}} = \frac{4}{3} \pi R^3 \] The probability \( P \) that a randomly chosen point inside the sphere is closer to the center than to the surface is the ratio of the volume of the inner sphere to the volume of the entire sphere: \[ P = \frac{V_{\text{inner}}}{V_{\text{total}}} = \frac{\frac{1}{6} \pi R^3}{\frac{4}{3} \pi R^3} = \frac{\frac{1}{6}}{\frac{4}{3}} = \frac{1}{6} \cdot \frac{3}{4} = \frac{1}{8} \] Thus, the probability that a randomly chosen point inside the sphere is closer to the center than to its surface is \( \frac{1}{8} \).
67.A point is randomly chosen inside a cube with side length 𝑎. What is the probability that the point is closer to one of the vertices than to the center of the cube?
Sol.
68.Imagine you have a number line that ranges from -1 to 1. You randomly pick k points on this line. What is the expected distance of the closest point to the midpoint of the line?
Sol.
Project 5- The Dart Game
Module H
69.Plot and find the distance between points using Geogebra: \(A(1,2)\), \(B(2,3)\), and \(C(5,9)\).
Sol.
Create points on the graph and find the distances between them using the distance tool from the toolbar.70.Using Geogebra, which two points are the closest ones? What’s the distance between them?
Sol.
The ones with the minimum distance between them will be the closest ones. Find them and check the distance.71.Add four more points: \(D(0,-1)\), \(E(4,11)\), \(F(8,12)\), \(G(-3,6)\) to your graph. What’s the closest pair now?
Sol.
Follow the similar approach for finding the closest pairs.
72.Suppose we have 10 points. How many pairs of points do you have to consider for finding the closest pair?
Sol.
Similar to the previous question, the total combinations possible will be \(10 * 9 / 2 = 45\).
73.What is the Y sorted order (by default assume ascending) of points \(A\), \(B\), \(C\), \(D\), \(E\)?
Sol.
For finding the Y - sorted order, we will consider only ordinate values of the coordinates mentioned.\(A = 2\), \(B = 3\), \(C = 9\), \(D = -1\), \(E = 11\)
The ascending order of these values will be:
$$D < A < B < C < E$$
74.Plot a line \(L\) parallel to the Y-axis passing through the middle point in the X sorted order of the above points. Divide the set of points into left and right regions around the line.
Sol.
X - Sorted Order = \(G < D < A < B < E < C < F\)Middle Member = \(B\) $$L : x = 2$$ Left Region = \(D, A, G\)
Right Region = \(E, C, F\)
75.Find the closest pair of points in the left region and right region. What’s the minimum distance (say \(d\)) out of the two distances?
Sol.
Closest Pair in Left Region = \(A & D\)Closest Pair in Right Region = \(C & E\)
Minimum Distance = \(2.24 units\), corresponding to the points \(C & E\)
76.Consider a band of width \(2d\) around the Line \(L\). Find the closest pair in this band. Compare this distance with \(d\), the minimum value of the corresponding closest pair of our graph. Is the answer the same as the brute-force method you applied in question 71? (This divide and conquer method is known as the closest pair algorithm).
Sol.
This band limits the number of points but still the approach remains the same.The closest pair is also the same as achieved in the question mentioned.
77.Astronomers have recorded the positions of stars in a 3D coordinate system where each star is represented as a point. Given the coordinates of stars \((1,2,3)\), \((4,5,6)\), \((6,7,8)\), \((10,11,12)\), find the closest pair of stars.(Use Geogebra).Is the closest pair algorithm valid here?
Sol.
The method for 3 - Dimensional points is similar to that of 2 - Dimensional points.
78.If \(F(0) = 0\), \(F(1) = 1\), \(F(n) = F(n-1) + F(n-2)\) for \(n \geq 2\), find the value of \(F(5)\).
Sol.
\(F(5) = F(4) + F(3) = F(3) + F(2) + F(2) + F(1) = ... = 5(F(1)) = 5\)
79.Dry run and find the output of the following python code:
def f(n):
if n == 0:
return 1
return n * f(n-1)
print(f(5))
Sol.
\(F(5) = 5 * F(4) = ... = 5 * 4 * 3 * 2 * 1 * F(0) = 5 * 4 * 3 * 2 * 1 = 120\)
80.Does the closest pair algorithm assume that the \(x\) coordinates (and \(y\) coordinates) of the points are distinct? Is there a problem with the \(O( nlog(n))\) performance if they are not distinct(do we have to handle this special case seprately in our algorithm)?
Sol.
81.Given a set of points where most points are far apart, but a few points are very close to each other,can you develop an algorithm more efficient from our original algorithm to find the closest pair in this special case.
Sol.
Module I
82.Do you know the idea of equally likely events? What are these? Can you think of any event which is not equally likely?
Sol.
Equally likely events are events that have the same probability of occurring. When we say that events are equally likely, it means that each event has the same chance or likelihood of happening. For instance, coin toss, rollong a fair die, choosing a card from a deck of well-shuffled cards. An example of events not being equally likely may include result of sport games, which depends on various factors like relative strangths of the teams, the condition of the field, etc.
83.You are given two coins .What is the probability that one head and one tail shows up on tossing?
Sol.
To determine the probability of getting one head and one tail when tossing two coins, we need to consider all possible outcomes and then identify the outcomes that match the desired event (one head and one tail). When tossing two coins, each coin can land on heads (H) or tails (T). Therefore, the possible outcomes are: - (H, H) - (H, T) - (T, H) - (T, T) We are interested in the outcomes where there is one head and one tail. These outcomes are: - (H, T) - (T, H) The probability \( P \) of an event is given by the ratio of the number of favorable outcomes to the total number of outcomes. \[ P(\text{one head and one tail}) = \frac{\text{Number of favorable outcomes}}{\text{Total number of outcomes}} = \frac{2}{4} = \frac{1}{2} \]84.In a class in which all students practise at least one sport, 60% of students play soccer or basketball and 10% practice both sports. If there is also 60% that do not play soccer, calculate the probability that a student chosen at random from the class:
- Plays soccer only.
- Play basketball only.
- Plays only one of the sports.
- Plays neither soccer nor basketball.
Sol.
To solve this problem, we can use the principle of inclusion-exclusion and basic probability rules. Given Data: - Let \( S \) represent the set of students who play soccer. - Let \( B \) represent the set of students who play basketball. - \( P(S \cup B) = 0.60 \) (60% of students play soccer or basketball) - \( P(S \cap B) = 0.10 \) (10% of students play both sports) - \( P(S') = 0.60 \) (60% of students do not play soccer)1. Probability that a student plays soccer only:
\( P(S \setminus B) \). \[ P(S \setminus B) = P(S) - P(S \cap B) \] Since \( P(S') = 0.60 \), the probability of playing soccer, \( P(S) \), is: \[ P(S) = 1 - P(S') = 1 - 0.60 = 0.40 \] Therefore: \[ P(S \setminus B) = P(S) - P(S \cap B) = 0.40 - 0.10 = 0.30 \] 2. Probability that a student plays basketball only:
\( P(B \setminus S) \). \[ P(B \setminus S) = P(B) - P(S \cap B) \] We need to find \( P(B) \). Using the principle of inclusion-exclusion for \( P(S \cup B) \): \[ P(S \cup B) = P(S) + P(B) - P(S \cap B) \] Given \( P(S \cup B) = 0.60 \): \[ 0.60 = 0.40 + P(B) - 0.10 \] Solving for \( P(B) \): \[ 0.60 = 0.30 + P(B) \] \[ P(B) = 0.30 \] Therefore: \[ P(B \setminus S) = P(B) - P(S \cap B) = 0.30 - 0.10 = 0.20 \] 3. Probability that a student plays only one of the sports:
This is the probability of playing either soccer only or basketball only, \( P((S \setminus B) \cup (B \setminus S)) \). \[ P((S \setminus B) \cup (B \setminus S)) = P(S \setminus B) + P(B \setminus S) \] Using the results from above: \[ P((S \setminus B) \cup (B \setminus S)) = 0.30 + 0.20 = 0.50 \] 4. Probability that a student plays neither soccer nor basketball:
Given \( P(S \cup B) = 0.60 \), the probability of playing neither sport, \( P((S \cup B)') \), is: \[ P((S \cup B)') = 1 - P(S \cup B) = 1 - 0.60 = 0.40 \] Summary of Probabilities:
- Plays soccer only: \( 0.30 \)
- Plays basketball only: \( 0.20 \)
- Plays only one of the sports: \( 0.50 \)
- Plays neither soccer nor basketball: \( 0.40 \)
85.Imagine you are writing your semester exams . To write an exam , there are 70% chances that an alarm clock will wake you up successfully. If you hear the alarm clock then there are 95% chances you will write the exam and if you don’t hear the alarm the chances are 50%.
a)If you have written the exam what are the chances that you heard the alarm clock?
b) What are the chances that you didn’t hear the alarm if you have not written the exam?
Sol.
Let's denote: - A: event that you hear the alarm clock. - B: event that you write the exam. Given: - P(A) = 0.7 (probability of hearing the alarm) - P(B|A) = 0.95 (probability of writing the exam given you heard the alarm) - P(B|¬A) = 0.5 (probability of writing the exam given you didn't hear the alarm) (a) To find the probability that you heard the alarm clock given that you wrote the exam, we can use Bayes' theorem: \[P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)}\] First, we need to find \(P(B)\): \[P(B) = P(B|A) \cdot P(A) + P(B|¬A) \cdot P(¬A)\] \[= 0.95 \times 0.7 + 0.5 \times (1-0.7)\] \[= 0.665 + 0.15\] \[= 0.815\] Now, we can calculate \(P(A|B)\): \[P(A|B) = \frac{0.95 \times 0.7}{0.815}\] \[≈ \frac{0.665}{0.815}\] \[≈ 0.816\] So, the probability that you heard the alarm clock given that you wrote the exam is approximately 81.6%. (b) To find the probability that you didn't hear the alarm if you didn't write the exam: \[P(¬A|¬B) = \frac{P(¬B|¬A) \cdot P(¬A)}{P(¬B)}\] We know: \[P(¬B|¬A) = 1 - P(B|¬A) = 1 - 0.5 = 0.5\] \[P(¬A) = 1 - P(A) = 1 - 0.7 = 0.3\] \[P(¬B) = 1 - P(B) = 1 - 0.815 = 0.185\] Now we can calculate \(P(¬A|¬B)\): \[P(¬A|¬B) = \frac{0.5 \times 0.3}{0.185}\] \[≈ \frac{0.15}{0.185}\] \[≈ 0.811\] So, the probability that you didn't hear the alarm if you didn't write the exam is approximately 81.1%.
86.Lets say an investment company “Future Wealth“ analyses stocks and predicts whether their price will go up or down. So far, half of the stocks analysed by the company have gone up, 3/4 of the stocks that went up were correctly predicted to go up, and 2/5 of the stocks that went down were incorrectly predicted to go up. Suppose that the company tells you that it will go up. Compute the probability that the stock will indeed go up.
Sol.
To solve this problem, we can use Bayes' Theorem. Let's define the following events: - \(U\): The stock price goes up.- \(D\): The stock price goes down.
- \(P\): The company predicts that the stock price will go up.
Given data:
- \(P(U) = 0.5\) (half of the stocks have gone up)
- \(P(P \mid U) = \frac{3}{4}\) (3/4 of the stocks that went up were correctly predicted to go up)
- \(P(P \mid D) = \frac{2}{5}\) (2/5 of the stocks that went down were incorrectly predicted to go up)
We need to compute \(P(U \mid P)\), the probability that the stock price will go up given that the company predicts it will go up.
Using Bayes' Theorem:
\[ P(U \mid P) = \frac{P(P \mid U) \cdot P(U)}{P(P)} \] First, we need to find \(P(P)\), the total probability that the company predicts the stock will go up. This can be calculated using the law of total probability: \[ P(P) = P(P \mid U) \cdot P(U) + P(P \mid D) \cdot P(D) \]
Given:
- \(P(U) = 0.5\)
- \(P(D) = 1 - P(U) = 0.5\)
- \(P(P \mid U) = \frac{3}{4} = 0.75\)
- \(P(P \mid D) = \frac{2}{5} = 0.4\)
Substitute these values into the equation for \(P(P)\): \[ P(P) = 0.75 \cdot 0.5 + 0.4 \cdot 0.5 = 0.375 + 0.2 = 0.575 \]
Now, use Bayes' Theorem to find \(P(U \mid P)\): \[ P(U \mid P) = \frac{0.75 \cdot 0.5}{0.575} = \frac{0.375}{0.575} \approx 0.6522 \]
So, the probability that the stock will indeed go up given that the company predicts it will go up is approximately \(0.6522\) or \(65.22\%\).
87.Imagine you are a bettor. You are watching a race between two horses A and B. Let’s say five races are conducted. Construct any three hypotheses defining winning probabilities of A and B. What confidence do you have in each of your hypotheses to be true? Lets say , out of 5 races A wins 3 and B wins the remaining 2 (AAABB). Then after 5 races , in which of your hypotheses will you have maximum confidence. As per your new hypothesis which horse has more chances to win the 6th round .
Sol.
Sure, let's create three hypotheses about the winning probabilities of horses A and B:1. Hypothesis 1: A is the stronger horse.
- Confidence: Moderate
- In this hypothesis, I believe that horse A has a higher probability of winning each race compared to horse B.
2. Hypothesis 2: B is the stronger horse.
- Confidence: Moderate
- Here, I assume that horse B has a higher probability of winning each race compared to horse A.
3. Hypothesis 3: A and B have equal chances of winning.
- Confidence: Low
- This hypothesis suggests that both horses have an equal probability of winning each race.
After observing the outcomes of the 5 races (A wins 3, B wins 2), my confidence level in each hypothesis shifts:
1. Hypothesis 1: A is the stronger horse.
- Increased Confidence: High
- Since horse A won more races, I'm more confident in this hypothesis being true.
2. Hypothesis 2: B is the stronger horse.
- Decreased Confidence: Very Low
- With B winning fewer races, my confidence in this hypothesis decreases.
3. Hypothesis 3: A and B have equal chances of winning.
- Decreased Confidence: Low
- Given the unequal outcomes, this hypothesis seems less likely.
Given that Hypothesis 1 now has the highest confidence, I'd predict that in the 6th round, horse A would have a higher chance of winning.
88.You’re training a spam filter . You have data on the frequency of certain words in both spam and non-spam emails. How would you update your beliefs about an email being spam or not spam based on the presence of specific words?Let’s say initially chances of an email being spam is 40%.
Data: Word “free” appears in 80% of spam emails and 5% of non-spam emails
Sol.
To update my beliefs about an email being spam or not spam based on the presence of specific words, such as "free," I would use Bayesian inference.Given the initial probability of an email being spam (\( P(\text{Spam}) = 0.4 \)), I can calculate the updated probability using Bayes' theorem:
\[ P(\text{Spam}|\text{word "free"}) = \frac{P(\text{word "free"}|\text{Spam}) \times P(\text{Spam})}{P(\text{word "free"})} \]
Where:
- \( P(\text{Spam}|\text{word "free"}) \) is the probability that an email is spam given the word "free" is present.
- \( P(\text{word "free"}|\text{Spam}) = 0.8 \) is the probability of the word "free" appearing in spam emails.
- \( P(\text{Spam}) = 0.4 \) is the initial probability of an email being spam.
The overall probability of the word "free" appearing in all emails can be calculated as:
\[ P(\text{word "free"}) = P(\text{word "free"}|\text{Spam}) \times P(\text{Spam}) + P(\text{word "free"}|\text{Non-Spam}) \times P(\text{Non-Spam}) \]
Given that the word "free" appears in 80% of spam emails and 5% of non-spam emails, let's calculate \( P(\text{word "free"}) \):
\[ P(\text{word "free"}) = (0.8 \times 0.4) + (0.05 \times 0.6) = 0.32 + 0.03 = 0.35 \]
Now, we can use Bayes' theorem to update the probability of an email being spam given the word "free" is present:
\[ P(\text{Spam}|\text{word "free"}) = \frac{0.8 \times 0.4}{0.35} \approx 0.914 \]
So, if the word "free" is present in an email, the updated probability of that email being spam is approximately 91.4%.
89.Suppose that we use a perceptron to detect spam messages. Let’s say that each email message is represented by the frequency of occurrence of keywords, and the output is +1 if the message is considered spam.
a) Can you think of some keywords that will end up with a large number of positive weight in the perceptron?
b)How about keywords that will get a negative weight?
c)What parameters in the perceptron directly affects how many border-line messages end up being classified as spam?
Sol.
(a) Keywords that are frequently associated with spam messages are likely to end up with large positive weights in the perceptron. Some examples of such keywords could be: "free", "discount", "limited offer", "click here", "urgent", "guaranteed", "cash", "prize", "win", "money", "call now", "buy now", "order now", etc. These words often appear in promotional or phishing emails, which are typically classified as spam.(b) Conversely, keywords that are commonly found in non-spam messages and are indicative of legitimate communication are likely to get negative weights in the perceptron. Examples of such keywords could include: "important", "meeting", "schedule", "invoice", "receipt", "conference", "report", "agenda", "project", "proposal", "contact", "thank you", "best regards", etc.
(c) The parameter in the perceptron that directly affects how many borderline messages end up being classified as spam is the bias term. The bias term determines the threshold for the perceptron's decision boundary. If the bias term is set too low, more messages will be classified as spam, including some borderline ones. Conversely, if the bias term is set too high, fewer messages will be classified as spam, potentially missing some actual spam messages. Adjusting the bias term allows for fine-tuning the trade-off between false positives and false negatives in the classification task.
90.Lets have some parameters 3.1, 4.2 and 4 and the corresponding weights 5,1,and 3 respt. Calculate the weighted sum.
Sol.
To calculate the weighted sum given the parameters and corresponding weights, we multiply each parameter by its corresponding weight and then sum the results. Given: - Parameter 1: 3.1, Weight: 5 - Parameter 2: 4.2, Weight: 1 - Parameter 3: 4, Weight: 3 The weighted sum is calculated as follows: Weighted sum = (Parameter 1 * Weight 1) + (Parameter 2 * Weight 2) + (Parameter 3 * Weight 3) = (3.1 * 5) + (4.2 * 1) + (4 * 3) = 15.5 + 4.2 + 12 = 31.7 So, the weighted sum is 31.7.91.Suppose you have set of numbers ranging from -infinity to infinity. Will it be easy to plot them in a limited screen size and compare them?
Sol.
Plotting a set of numbers ranging from negative to positive infinity can be challenging due to the vast range of values involved. Even if you narrow down the range to a finite interval, such as from -1000 to 1000, the sheer number of data points may make it difficult to visualize and compare them effectively on a limited screen size.
92.Will simply dividing them by some large number work?
Sol.
No, it won't work as the points might start overlapping as they may be too big that the closer points come too much closer and start to overlap.
93.Can you think of a way to fit these numbers in some finite range? Think about some kind of functions?
Sol.
One approach to fitting an infinite range of numbers into a finite range is to use a transformation function. Using sigmoid or similar functions can be effective in fitting a wide range of numbers into a finite range. The sigmoid function, for example, has a characteristic S-shaped curve that maps input values to an output range between 0 and 1. The sigmoid function can be represented by the formula:\[ f(x) = \frac{1}{1 + e^{-x}} \]
Where:
- \( f(x) \) is the output of the sigmoid function for input \( x \).
- \( e \) is the base of the natural logarithm, approximately equal to 2.71828.
- \( x \) is the input value.
You can use this function to map input values to an output range between 0 and 1, which can be useful for various data transformation tasks.
Module J
94.Write the number 25 in its binary form.
Sol.
\(11001\)95.Given a text data, how will you convert it into binary form?
Sol.
We have to use some algorithm to efficiently find a transformation from text to binary for each character. Can you think of any such algorithm?96.What if we use the binary code for each character according to the ASCII convention? How much space would each character take up?
Sol.
Let us discuss how ASCII algorithm works. First, convert each character in the text into its corresponding ASCII value. ASCII (American Standard Code for Information Interchange) is a character encoding standard that represents text in computers. Then, convert each ASCII value into its binary representation. This is typically done by converting the decimal value to binary. But here, each character in ASCII convention takes up 8 bits of space. This is a fixed-width encoding scheme, where each character is represented using the same amount of space.97.Suppose I take the following notation for the letters s, o, n, h and a:
s: 00
o: 001
a: 010
h: 011
n: 1
Decode the following string: ‘00011010110011’
Sol.
The given string can be broken w.r.t. the codes given as:\((A)\) 00, 011, 010, 1, 1, 001, 1
\((B)\) 00, 011, 010, 1, 1, 00, 1, 1
This led us to 2 different answers.
98.Do you observe that the above string can have 2 different interpretations?
Sol.
Continuing from the previous solution, we get two different interpretations:\((A)\) shannon
\((B)\) shannsnn
99.Can this issue occur if we take each code of the same length? Can you define one such coding for the above example, i.e., s, o, n, h and a? At least how many digits would you have to take for each character?
Sol.
No, if we take each code of the sae length, there is no possiblity of two different interpretations of the string.For the given example with the codes "s", "o", "n", "h", and "a", let's consider a simple substitution cipher where each letter is replaced by a numeric code. Since there are 5 distinct codes (s, o, n, h, a), we would need to represent each character using at least 3 digits to ensure that each code is uniquely identifiable.
Here's one possible encoding scheme:
- "s" is represented by "001"
- "o" is represented by "010"
- "n" is represented by "011"
- "h" is represented by "100"
- "a" is represented by "101"
With this encoding scheme, each character is represented by 3 digits, ensuring that there are no ambiguities in decoding.
100.Observe that for 5 unique letters, I cannot have unique binary representations if I take length of each notation exactly 2. Why?
Sol.
If we use 2 bits for each letter, we have a total of 5 unique letters: “a,” “b,” “c,” “d,” and “e.”With 2 bits, we can represent up to 4 different values (since \(2^2=4\)).
Therefore, we need at least 5 unique binary codes to represent all 5 letters uniquely.
101.Suppose you go to buy apples. There are three varieties of apples available. Your mom has given you a task that you have to buy 2 apples of any one type, 3 of the any other type, and 5 of the third. How will you minimise the total money spent?
Sol.
To minimize the total money spent, we should choose the cheapest option for the largest quantity required:1. Buy 5 apples of one type:
- Choose the cheapest type. Let's say it's type A.
2. Buy 3 apples of another type:
- Choose the cheapest type again. Let's say it's type B.
3. Buy 2 apples of the third type:
- This is the last remaining type, type C.
So, you would buy 5 apples of type A, 3 apples of type B, and 2 apples of type C to minimize the total money spent.
102.Given the text ‘this is a new experience’. Write the frequency distribution of these characters for this sentence.
Sol.
Following is the frequency distribution of the characters in the text 'this is a new experience':t: 1
h: 1
i: 3
s: 2
: 4 (space)
a: 1
n: 2
e: 4
w: 1
x: 1
p: 1
r: 1
c: 1
103.To which characters should I give a shorter notation as compared to the others?
Sol.
The characters with the maximum frequency must be given shorter notations in order to minimize the space they take together.104.Do you observe that the issue occurred in fifth question was because the code of ‘s’ is a prefix of the code for ‘o’?
Sol.
Certainly, due to the code of 's' being prefix of the code of 'o', there were two possiblilities, which did arise as the code of 's' was itself a part of the code of 'o' and 'o' can also be broken down into 's' and the rest of it.105.What all do you think should be the properties of a proper encoding rule?
Sol.
In a proper encoding rule, there should not be any repitition of codes so that there is no confusion at all for the codes of various characters.The encoding rule should be consistent, meaning the same input should always produce the same output.
The encoded data should be as compact as possible, reducing storage and transmission requirements. This is particularly important for large datasets or in bandwidth-constrained environments.
Also for sensitive data, the encoding should provide a level of security, ensuring that the encoded data is not easily interpretable by unauthorized parties. This may involve incorporating encryption techniques.
106.Get some quite basic knowledge about trees as data structures.
Sol.
Trees are hierarchical data structures composed of nodes connected by edges.Trees consist of a root node, which is the topmost node in the hierarchy, and zero or more child nodes connected to it.
Parent: A node that has child nodes connected to it. Every node in a tree, except the root, has exactly one parent.
Leaf: A node with no children.
Depth: The level of a node in the tree. The depth of the root node is 0, and the depth increases as you move away from the root.
Height: The maximum depth of any node in the tree. It represents the longest path from the root node to a leaf node.
Binary Tree: A special type of tree where each node has at most two children, known as the left child and the right child.
107.Observe that the lower is a node in a tree, the more is the time you would take to reach till it from the top node.
Sol.
This observation can be justified with the fact that the distance increases between the parent node and the root node as the root node keeps on going down further.As the ditsnce increases, the ti e taken will also correspondingly increase.
Project 4- Huffman Encoding
Module K
108.In a huge network of webpages, how does the browser decides which webpage should be appeared on top?
Sol.
The pages inside of a huge network of webpages are ranked on the basis of core concept of PageRank.PageRank is based on the idea that the importance of a webpage can be determined by the number and quality of links to it. In essence, it treats links from other webpages as "votes" for the target page's importance. However, these votes are weighted by the importance of the pages they come from.
109.Read about the Algorithms Random Walk and Equal points Distribution and try to figure out how they are able to find the importance of the webpages?
Sol.
RANDOM WALK: Imagine a scenario where a person starts on a random web page and begins clicking on links randomly. Eventually, this random process will converge towards certain pages more frequently than others. Pages that are frequently visited during this random walk are considered more important because they are more likely to be stumbled upon by users.EQUAL POINTS DISTRIBUTION: In this approach, each web page starts with an equal amount of importance points. As the algorithm iterates through the network of pages, it distributes points based on various factors like incoming links, outgoing links, and possibly other criteria like the relevance of content. Pages that are linked to by many other pages will accumulate more points, indicating their importance.
110.Are you able to visualize that the Equal points distribution method is nothing but a repetitive matrix operation on a vector?
Sol.
The iterative calculation of PageRank, can be visualized as a repetitive matrix operation on a vector. The web's link structure is represented by a transition matrix \( M \), where each element \( M_{ij} \) indicates the probability of moving from one page to the other.Starting with an initial PageRank vector \( P \), where each element corresponds to the PageRank of a page, the algorithm updates this vector through matrix multiplication. The PageRank vector \( P \) is recalculated iteratively using the formula \( P_{new} = M \cdot P_{old} \). In each iteration, the new PageRank vector is obtained by multiplying the transition matrix \( M \) with the current PageRank vector \( P \). This process continues until \( P \) converges to a stable distribution. This repetitive multiplication demonstrates how the Equal Points Distribution method leverages matrix operations to determine the final PageRank values.
111.Will the points of the webpages calculated the Equal points distribution method converge? If yes how can you be sure about it?
Sol.
112.Is this convergence dependent on the initial vector?
Sol.
The initial vector \( P \) can be any probability distribution, often starting with equal values or completely unbalanced values.Because of the properties of the transition matrix \( M \), the process \( P_{new} = M \cdot P_{old} \) will converge to the same stationary distribution for any initial vector \( P \).
The convergence of the PageRank values is guaranteed by the structure and properties of the transition matrix \( M \) and is not dependent on the initial vector. Any starting vector will eventually lead to the same steady-state distribution
113.If you have three websites, A, B, and C, and all are linked to each other, what happens to the importance of each website if:
Website A is linked to by both B and C.
B is linked to by A.
C is linked to by A.
How does the number of links pointing to a website affect its perceived importance?
Sol.
The importance or perceived authority of a website is often measured by search engines through a metric called "PageRank," which considers the number and quality of links pointing to that website. In this scenario:1. Website A: Since it is linked to by both B and C, it gains importance from both of them. Having multiple incoming links suggests that it might be more authoritative or relevant. Therefore, Website A would likely have higher perceived importance compared to the others.
2. Website B: It is linked to by A, which adds to its importance. However, it doesn't have any other external links in this scenario, so its perceived importance might be lower than Website A.
3. Website C: Similarly, it is linked to by A, which adds to its importance. However, like Website B, it doesn't have any other external links in this scenario, so its perceived importance might be lower than Website A. The number of links pointing to a website does affect its perceived importance. Generally, more incoming links from reputable sources indicate higher authority and relevance in the eyes of search engines. However, the quality of those links also matters. A few high-quality links from authoritative websites can outweigh many low-quality links.
114.Given 4 buckets (A, B, C, and D):
A passes its coins to B and C
B passes its coins to D
C passes its coins to A
D passes its coins to B
If each bucket starts with 1 coin, calculate the number of coins in each bucket after first round and second round.
Sol.
After First Round:A = 1; B = 1.5; C = 0.5; D = 1
After Second Round:
A = 0.5; B = 1.5; C = 0.5; D = 1.5
115.In both the algorithms (Random Walk and Equal Distributions) what problem would you face if we have some highly connected nodes? Would it affect the evaluation of other nodes?
Sol.
In both the Random Walk and Equal Distributions algorithms used for calculating PageRank, highly connected nodes can pose challenges and potentially affect the evaluation of other nodes. This issue primarily arises due to the potential for bias introduced by the presence of highly connected nodes, because of which random walkers may frequently get trapped in these nodes, leading to an uneven distribution of visits across the network.Highly connected nodes tend to accumulate more random walkers, leading to inflated PageRank values for these nodes. Consequently, the importance of other nodes may be underestimated, as random walkers are less likely to visit them.
116.What modifications in the algorithm can you think to solve this problem?
Sol.
Project 2- PageRank
Project 3- Recommender System
Project 6- On Geogebra, take a vector in the 3-D axis system starting from the origin and going to some random point. Plot the plane passing through that point and perpendicular to the vector. Suppose you drop a water droplet randomly somewhere on this plane. Plot the direction (as a vector) in which the droplet moves on the plane. This vector should accordingly vary as you vary the coordinates of the random point you took in the beginning, i.e., do everything in the parametric format. Do not use Mathematics anywhere…
Module L
117.How does a computer represent an image?
Sol.
Are you able to relate this with matrices? If yes, then is this matrix invertible?
Sol.
119.Given a 2*2 matrix, what is the probability that the matrix is non-invertible?
Sol.
120.What would happen if I randomly remove one pixel form it, would it make any change? What about removing two, three, four… pixels?
Sol.
121.How many pixels you can remove in this way? When would you stop?
Sol.
122.Can we retrieve the removed pixels?
Sol.
123.How much difference do you expect in two adjacent pixels in an image?
Sol.
124.Can you think of a systematic way of removing pixels from the image?
Sol.
125.Can you retrieve the removed pixels back in this way?
Sol.
Project 7- Data Compression 1
Module M
126.Recall linear transformation that you studied in previous modules. What do they do?
Sol.
127.Let a vector \(v=[3,4]\) and matrix be \(A= [[1/ \sqrt{2},-1/ \sqrt{2}],[1/ \sqrt{2},1/ \sqrt{2}]]\), find Av, what do you observe?
Sol.
128.Let a vector \(v=[3,4]\) and matrix be \(B= [[ \sqrt{3}/2,-1/2],[1/2,\sqrt{3}/2]]\) find Bv, what do you observe?
Sol.
129 What similarity can you observe in matrix A and B?
Sol.
130.Let a vector \(b=[3,4]\) and a matrix \(D=[[2,0],[0,3]]\) find Db. Can you observe that the matrix D simply scaled the respective axis of the vector?
Sol.
131.Are you aware of orthogonal matrices? What properties do orthogonal matrices show?
Sol.
132.What is the relation between transpose and inverse of an orthogonal matrix?
Sol.
133.What do you get when you multiply \(A\) and \(A^T\)?
Sol.
134.Find the eigen vectors of \(AA^T\) for different matrices A, and find the common feature in these eigen vectors.
Sol.
135.Observe what does a matrix \(A =[[1,0],[0,1],[0,0]]\) do when applied to a vector in \(R^2\).
Sol.
136.Observe what does a matrix \(A =[[1,0,0],[0,1,0]]\) do when applied to a vector in \(R^3\).
Sol.
Project 8- Knapsack
Module N
137..What do you understand by convolution?Suppose we have two sets (A) and (B): \(A = \{1, 2, 3, 4\} , B = \{5, 6, 7, 8\}\) . What is \(A \ast B\) ? And what about\(B \ast A\)? Are they the same?
138.How do you convolve two matrices? Let two matrices be A and B. A=\(\left( \begin{matrix} 3 & 1 &-1 \\1 & 2 &0 \\1 & 1 & 8 \\\end{matrix}\right)\) and B = \(\left( \begin{matrix} 1 & 0 & -1\\4 & -2 & 0 \\6 & 5 & 1 \\\end{matrix}\right)\) then what is \(A \ast B\)?
139.What is the purpose of using filters on images?
140.a)How will you create a filter for horizontal edge detection?
b)How will you create a filter for diagonal edge detection?
c) What kind of values you need in a filter used for blurring an image?
141.Apply the following filter F on an image M and observe the dimensions of the output. Are the same as previous?
142.Given a \(32 \times 32 \times 32\) RGB image, calculate the output dimensions after applying a convolutional layer with 16 filters, each of size \(3 \times 3\), with a stride of 1 and with no padding. Also find the general formula.
143.What is purpose of applying a pooling layer on an image. How is it different from convolution layer?
144.a)Apply \(2 \ast 2\) Max pooling on the following image.
b) Apply \(2 \ast 2\) avg pooling on the following image.
c) What are the dimensions of the image after pooling? Does pooling change the depth of the image?
d)Why don’t we use Min pooling?
145.Given the following predicted probabilities and true labels, calculate the binary cross-entropy loss: Predicted probabilities=[0.7,0.2,0.1] True labels=[1,0,0]
146.When will this cross entropy loss be minimum?
147.For a weight W with a gradient\(\frac{\partial L}{\partial W} =0.01\), a learning rate α=0.1, and an initial weight \(W_{\text{o}} = 0.5\), compute the updated weight using gradient descent.
148.a) Differentiate \(\frac{1}{ 1 + e^{-x} }\) with respect to (x).
b) Differentiate \(-\log(2x^2)\) with respect to (x).
c) Differentiate \(\frac{e^i}{ \sum e^k }\) with respect to (i) and (j).
149.Given is a single neuron, let the loss L be \((\hat{z} - z)^2\), find \(\frac{\partial L}{\partial w_{11}}\) and \(\frac{\partial L}{\partial p_{2}}\)
.
150.Given is another simple neural network. What is the relation of each layer of the above neural network with the previous layer . explicitly write relation of each layer’s neurons with previous layers .
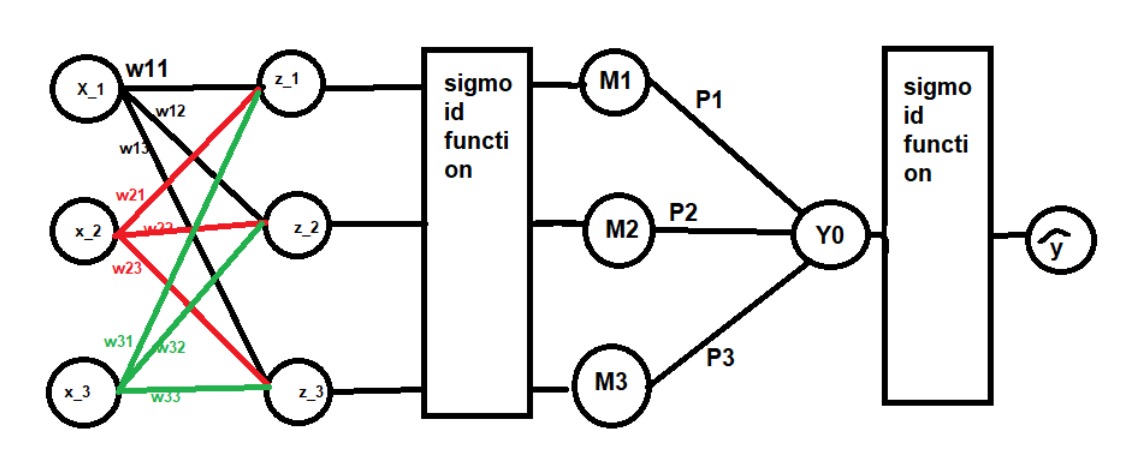
151.How will you deal with the backpropagation through the max pool layer in CNN?
Module O
152.Plot the line \(2x+3y+4=0\) and points A(-1,1), B(-1,2), C(-2,0). Infer from the plot: What will be the sign of the value of \(2x+3y+4\) at the points A, B, and C?
153.Consider the line \(mx+ny+p=0\) and find the distance of the line from the origin.
154.Consider the equation of line \(mx+ny+p=0\). If the equation of one of the lines at distance d is given as \(mx+ny+p=1\), then find the equation of the other line.
155.The equation of a line can also be written as w.x + b = 0 if we define w = [m, n] and x = [x, y]. Find the distance between w.x + b = 0 and w.x + b = 1.
156.If the equations of the left and right margins are w.x + b = -1 and w.x + b = 1 respectively, show that the condition for a data point to be correctly classified is \([ y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq 1 ]\) where \((y_i)\) is the class label of the data point \((\mathbf{x}_i)\).
157.From the above questions, can you formulate the optimization problem for a linear SVM?
158.What is the difference between hard margin and soft margin SVM?
159.What is the role of C in soft margin SVM?
160.What is the role of the kernel function in SVM?
161.Why is Support Vector Machines (SVM) better than other ML Classification Algorithms (like logistic regression)?
162.In the following figure, arrange the points 1, 2, 3, 4 in increasing order of their error (loss).
163.How can we use SVMs in Multi-Class Classification?